Děkuji za velmi přínosný analytický pohled programátora.
Placené SW řešení není problém, nikoli však programované na zakázku, to by se finančně nevyplatilo, protože se jedná o jednorázovou akci.
ABBYY SW vedu v patrnosti.
Prosím o vysvětlení, cituji: "diakritika dokreslována graficky". Není mi to jasné.
Dovolím si trochu diskusně oponovat a ještě prosím o reakce a případné dovysvětlení v kontexttu toho co níže doplňuji.
Add grafické PDF - Pochopeno správně, jedná se opravdu o skeny papírových dokumentů, takže ve výsledku se jedná o obrázek uvnitř PDF.
OCR řešení je nyní nežádoucí, vím o co jde, různé OCR SW znám, jsem praktik. Za nutné vidím analyzovat zdrojová PDF tak, jak jsou nyní a nemodifikovat je. Jakákoli modifikace zkomplikuje nebo zabrání porování s jinými výchozímy daty, tím spíš, že přibudou další kvanta dat a to už lidský mozek po pár takových procesech může vzdát. Proto je nejprve nutné porovnávat a odstranit duplicity v souladu s body 1 a 2.
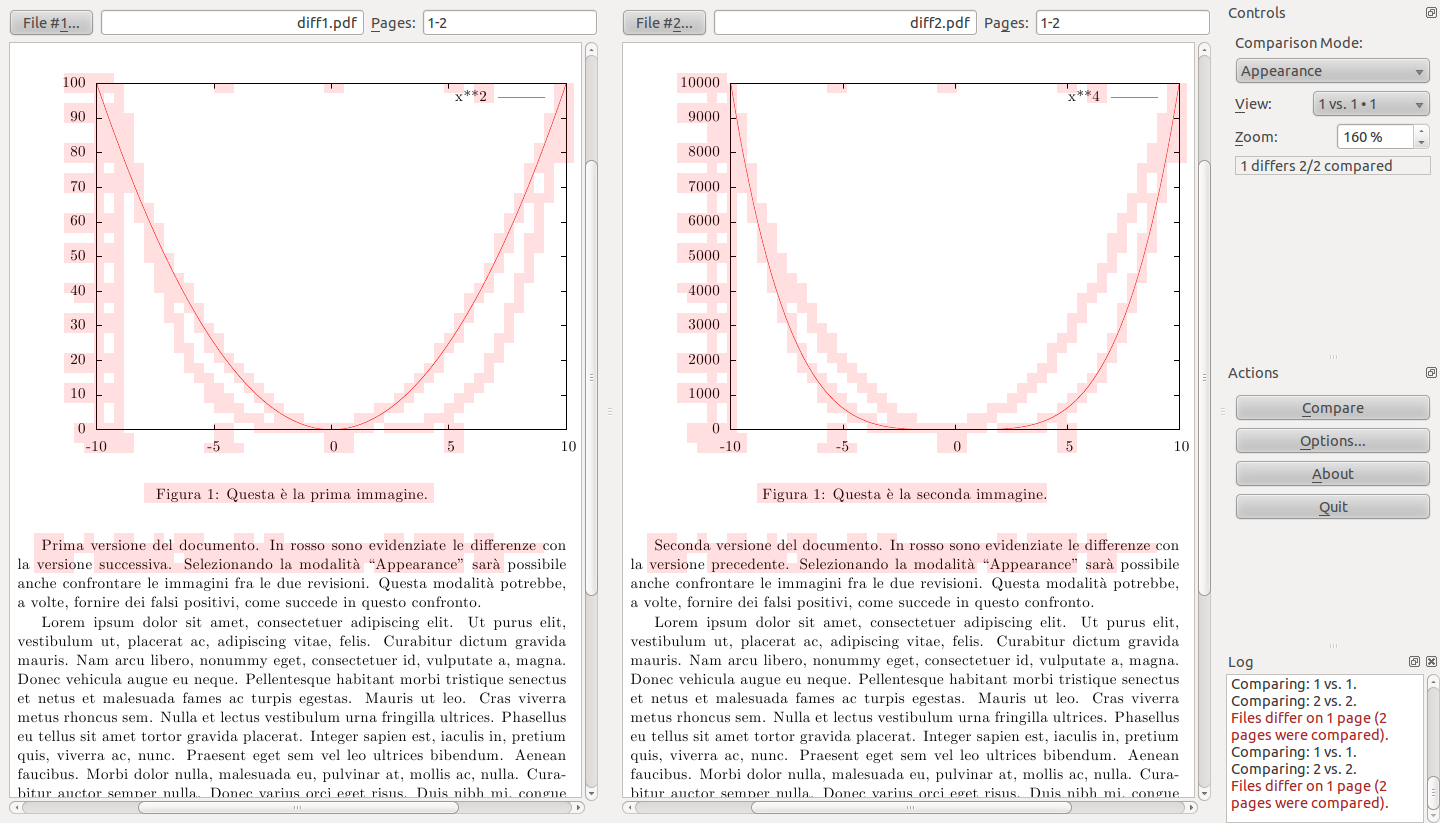
Add textové PDF - Nemyslím si, že by bylo nutné u textových PDF text exportovat externě (zníměna databáze) a dále s ním pracovat. Jistou naději dává principielní funkčnost programu DiffPDF. Je to pro mě nový SW a neznám ho. Pravděpodobně nedává šanci na zautoatizované zpracování více souborů a pracuje pouze se dvěmi PDF. Přesto je světlem na konci tunelu ...
Viz
https://www.qtrac.eu/diffpdf.html
https://www.qtrac.eu/diffpdf-foss.html
http://1.bp.blogspot.com/_YBnmJTR73Is/TN2R0ndLaMI/ AAAAAAAAAIA/knMcDdgb6BE/s1600/Schermata-DiffPDF-2. png
Neregistrovaný Přihlásit Registrovat
{kind=link}